Measures of Variability
Many courses require that students in undergraduate degree programs have a basic understanding of descriptive statistics. Descriptive statistics are statistics that collect, summarize, classify and present data. This guide gives you an overview of one type of descriptive statistics, measures of variability.
Measures of variability are measures that allow you to determine the degree of variation within a population or sample, determine how representative a particular score is of a data set, and determine the scope and validity of any generalizations you wish to make based on your research observations. The measures of variability discussed in this handout are:
- Range
- Variance
- Standard Deviation
Range
The range is the difference between the highest and lowest scores in a distribution. It is calculated by subtracting the lowest score from the highest score.
When is the range useful?
The range gives you a rough guide to the variability in a data set, as it tells you how a particular score compares to the highest and lowest scores.
Example:
14 40 42 47 49 51 71 81
(81 - 14) = 67
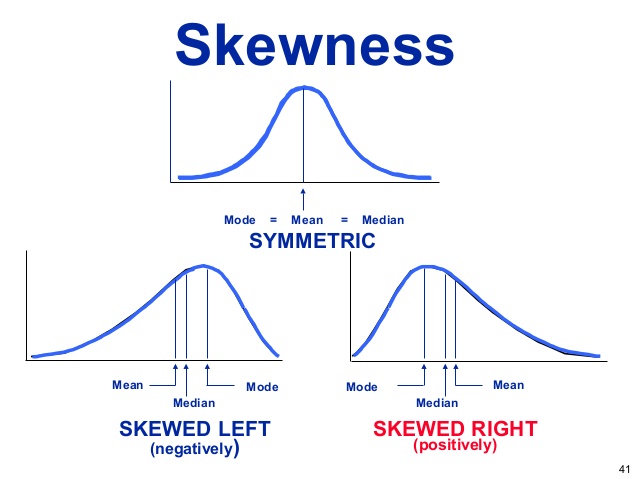
The range for this distribution would be (81 – 14) = 67. However, as you can see, 14 is an outlier and skews this distribution because, if it were not in the distribution, the range would be (81 – 40) = 41.
How else is the range useful
The range gives you a rough guide to the variability in a data set, as it tells you how a particular score compares to the highest and lowest scores within a data set. The range gives you only a limited amount of information, as data sets which are skewed towards a low score can have the same range as data sets which are skewed towards a high score, or those which cluster around some central score.
Sum of Squares
The sum of squares is a measure of variance or deviation from the mean.
It is calculated by summing of the squares of each score’s difference from the mean. The total sum of squares is another sum of squares; it considers not only the sum of squares from the factors, but also from randomness or error because the squaring of each score rids the equation of negative numbers. As you can see in the above example showing how to obtain the variance, step 5 requires you to find the sum of squares (SS).
EXAMPLE:
![]()
- Set of data: 2, 4, 6, 8
- Square each data point and add them together: 22 + 42 + 62 + 82= 4 + 16 + 36 + 64 =120
- Add together all of the data and square this sum: (2 + 4 + 6 + 8)2 = 400
- Divide this by the number of data points to obtain 400/4 =100
- We now subtract this number from 120: 120 - 100 = 20
- This gives us that the sum of the squared deviations is 20.
Standard Deviation (SD)
The standard deviation is the square root of the variance.
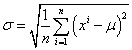
Unlike the variance, the standard deviation is measured in the same units as the raw scores themselves; therefore, one cannot just use the variance. This is what makes the standard deviation more meaningful. For example, it would make more sense to discuss the variability of a set of IQ scores in IQ points than in squared IQ points because they would not be congruent with the score's meaning.
Variables
EXAMPLE:
Data Set: 2, 4, 4, 4, 5, 5, 7, 9
Find the mean n = 5
Calculate the deviations of each data point from the mean, and square the result of each:
(2-5)2 = (-3)2 = 9
(4-5)2 = (-1)2 = 1
(4-5)2 = (-1)2 = 1
(4-5)2 = (-1)2 = 1
(5-5)2 = (0)2 = 0
(5-5)2 = (0)2 = 0
(7-5)2 = 22 = 4
(9-5)2 = 42 = 16
The variance is the mean of these values:
Standard deviation is equal to the square root of the variance:
√4 = 2
Variability
Variance is the degree to which scores vary from their mean. The variance uses every score in the data set. The variance is calculated by getting the average of the squared deviations from the mean.
Variance Equation
| Population Size | Sample Size | |
|---|---|---|
|
|
or |
|
To calculate the variance for a set of quiz scores:
- Find the mean (M).
- Find the deviation of each raw score from the mean (D). To do this, subtract the mean from each raw score. To check your calculations, sum the deviation scores. This sum should be equal to zero. **Note that deviation scores below the mean will be negative.
- Square the deviation scores (SS). We do this because by squaring the scores, negative scores are made positive and extreme scores are given relatively more weight.
- Find the sum of the squared deviation scores.
- Divide the sum by the number of scores. This yields the average of the squared deviations from the mean, or the variance Range.